记fofa爬虫工具开发篇
前沿
开发这个工具的原因单纯是在 大一(目前已经大三了)的时候 ,在用fofa搜索时,只能 搜索到 前 5 页,而且 github 上也找不到一个好点的爬虫,全是需要
会员的,我就想着弄一个 在不同城市之前收集目标,这样不仅仅 只有 50 条了(如下图),每个国家 的每个城市分别爬取50条那么 一条查询语句至少,得有 500条吧 也是受到一款工具的启发(那个大哥的博客找不到了)而且 fofa的域名更改后,就找不到一个像样的爬虫工具了,要么需要手动 要么 只能爬取5页,真low 所以基于这种现实问题开发了一个爬虫工具(现在高级会员可以直接下载10000条哈哈哈哈,噶,嗯 这个工具如果开注册会员的话 完美代替高级会员,如果你钱多当我没说,哈哈哈)那么接下来就开搞
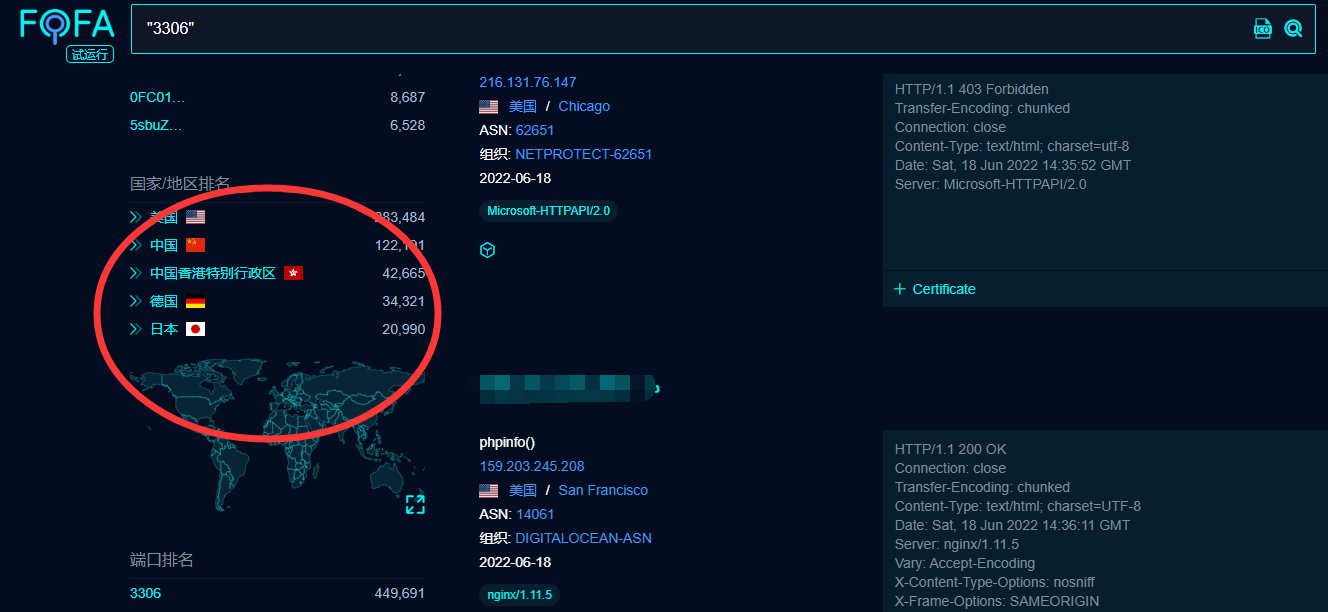
爬取的平台
目前有两个 fofaapp、fofaapi(这个写的太low了。。。。还是用别人写好了的吧 我这里给个链接 https://github.com/wgpsec/fofa_viewer 还是挺牛逼了别的不说)fofaapp 这个呢 就是面向 没钱的小朋友哈,我就属于其中的小朋友,所以我就有的摆了,来来来 下面说重点了
步骤
爬取个人网页
我的思路跟上面前沿介绍的需求差不多嘛,先 请求一次 检查一下cookies的正确性,请求https://fofa.info/personalData 把相关的信息拿到 主要的信息就是用户组(没钱的组)
def getUserinfo(self):
"""
:return: 个人信息
"""
userinfo = {}
requrl = self.url + '/personalData'
soup = self.getDriverSoup(requrl, True)
tags = soup.find_all(name="div", attrs={"class": "personList"})
apiTag = soup.find(name="span", attrs={"class": "apikeynumber"})
try:
if tags and apiTag:
userinfo['username'] = tags[1].contents[2].string
userinfo['useremail'] = tags[2].contents[2].string
userinfo['usergroup'] = tags[4].contents[2].string
userinfo['userApikey'] = apiTag.string.strip()
if (tags is None) or \
(userinfo['username'] is None) or \
(userinfo['useremail'] is None) or \
(userinfo['usergroup'] is None) or \
(userinfo['userApikey'] is None):
raise
except:
loguru.logger.warning("登录失败,检查cookies")
userinfo['usergroup'] = "未登录用户"
userinfo['username'] = "未登录用户"
userinfo['useremail'] = "未登录用户"
userinfo['userApikey'] = "未登录用户"
finally:
printfUserinfo(userinfo['username'], userinfo['useremail'], userinfo['usergroup'], userinfo['userApikey'])
if userinfo['usergroup'] == "未登录用户":
self.driver.close()
sys.exit()
return userinfo
getDriverSoup 这个方法就是为了得到 Beautisoup4(简称bs4)的soup 反正就是请求 到/personalData的内容,然后分别提取出来,如果你不会bs4的话,我之前也有写过一篇文章(抄的别人的 唉 不懂还是要学到的呗 链接:BS4-爬虫利器学习 好好读很快就学会了)tags = soup.find_all(name="div", attrs={"class": "personList"}) apiTag = soup.find(name="span", attrs={"class": "apikeynumber"}) 得到 信息对应的tag ,然后就是 错误判断了(我的错误判断错的很差,应该写统一抛出异常然后在一个文件下统一处理,如果你们看到了这里并且能个有心解决 欢迎来找我,我们一起制作 v4.0 嘿嘿)判断错误 就是cookies 错误
printfUserinfo 打印一下没别的功能
self.driver.close() 这个是selenium 为了爬取 网页上动态参数(有些数据 是网页上经过动态计算得来的,requests 爬取不到的) ,如果你不知道的话 额。。以后再说吧,我也没有写 文章,可以找一下其他的学习,不过不影响你接下来的观看
得到城市信息
就是图里面的信息 耶。里面的每一个标签都好找
def getCityUrls(soup):
"""
获得所有城市的url
:param soup: 第一次请求后的soup对象
:return:
"""
Cityurls = {}
countryLi = soup.find_all(name="li", attrs={"class": "countryLi"})
for tag in countryLi:
temp = {}
countryName = tag.find(name="div", attrs={"class": "titleLeft"}).a.string
countryName = str(countryName).strip()
cityTags = tag.find_all(name="div", attrs={"class": "tbDivList"})
for city in cityTags:
tempCity = {}
cityName = city.find(name="div", attrs={"class": "listCont table-label table-label-left"}).a.string
cityName = str(cityName).strip()
cityNum = city.find(name="div", attrs={"listCont table-label table-label-right"}).span.string
cityNum = str(cityNum).replace(',', '')
tempCity['href'] = city.find(name="div", attrs={"class": "listCont table-label table-label-left"}).a['href']
tempCity['Num'] = int(cityNum)
temp[cityName] = tempCity
Cityurls[countryName] = temp
return Cityurls
soup :第一次请求的结果text (这里必须用 selenium 的技术 动态请求),这里圈圈里面的参数都是动态获取的,所以动态请求一次就行,本篇文章主要讲思路,你不会的话,以后慢慢学 先掌握思路嘛
找到每个国家所在的tag - countryLi,从每个国家里面提取城市的名字 和城市城市中对应的数量 图二图二 代码在上面,最后在返回得到的城市信息以及城市请求的url
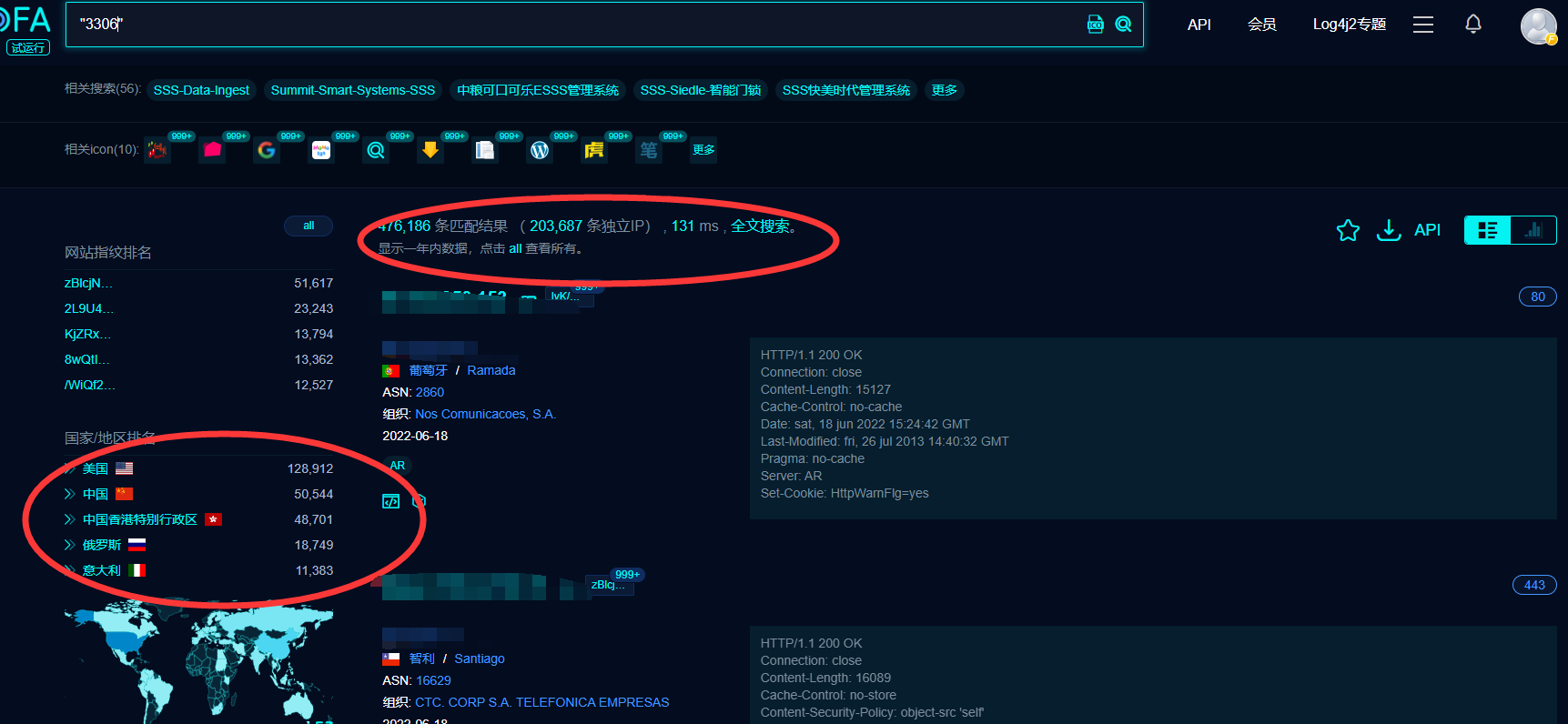
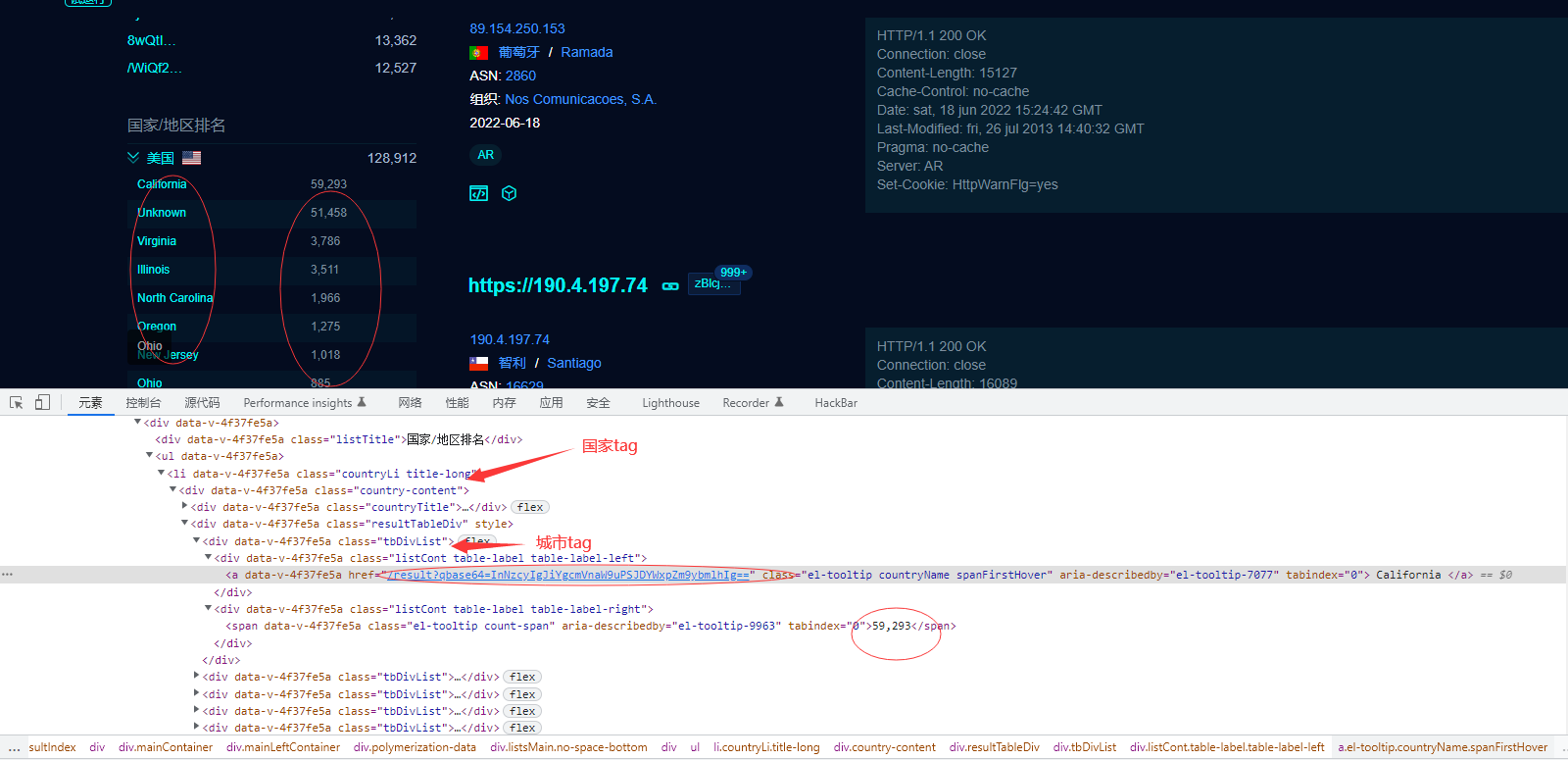
处理城市的请求页数
得到城市的url 就可以开始请求了,不过这里,如果你不想默认请求 想指定,请求多少页和每页的大小 就是这个(图里面),可以写个方法在 每次请求时修改这两个就行啦,然后请求第几页时就不会超过这个值了就不会报错了
def getNumPage(self, num):
"""
得到本次请求的 num page
:param num: 每个城市的num
:return: 是否获取成功
"""
self.num = int(num)
if self.num == 0:
return False
if 0 < self.num <= self.size:
self.page = 1
if self.num >= self.size:
self.page = int(self.num / self.size)
if (self.userGroup == "注册用户") & (self.page > 5):
self.size = 10
self.page = 5
return True
num: 就是第二步骤中获取的 cityNum
self.num 就是每个城市的总IP数量(这个参数没啥用就是为了约束self.page的)
self.page 这个就是每个城市的最大页数
逻辑都在代码里面了慢慢看吧,逻辑太简单了 但是要注意的时,如果是注册用户,就只能请求50条啦,(有条件可以开个注册会员! 注册会员就够了!!!!这个工具足够让你剩下那700了 )
return 嗯~ 当语句没有结果时返回False 有结果就返回True

处理请求
前面的工作做完了的话,就可以开始请求了 写个for循环挨个请求每个城市的url 以及page 我这里写的多线程,其实可以不用写多线程的,因为fofa禁爬虫,请求多了容易被fofa ban掉,不过写都写了 那就将就用呗,也是为了 优化嘛 多线程还是好一点的,大不了线程设置低一点(我设置的是2线程。。。。试过,最优了)
def futureThree(OK, maxWorkers, cookies, headers, reqUrl, size, page, reqCode, fileName, timeout):
"""
多线程函数 将 请求的url整理好 放入线程队列中
:param OK: 标志 请求
:param maxWorkers: 线程中最大线程
:param cookies: cookies值
:param headers: 请求头
:param reqUrl: 请求url
:param page: 页数
:param reqCode: 请求代码
:param fileName: 保存的文件名
:param timeout: 延时
:return: 成功请求多少页
"""
num = 0
if OK:
reqUrlList = [reqUrl + f"&page={pa + 1}&page_size={size}" for pa in
range(int(page))]
else:
reqUrlList = [reqUrl + f"/result?page={pa + 1}&page_size={size}&qbase64={Global.deBase64code(reqCode)}" for pa
in
range(int(page))]
pool = pocReq.ThreadPool(maxWorkers)
for url in reqUrlList:
pool.setTask(getReq, (url, cookies, headers, timeout,))
futures = pool.thread()
for future in futures:
a = future.result()
if not a:
continue
b = getUrlIp(soup=a, filename=fileName)
if not b:
continue
num = num + b
return num
def getUrlIp(soup, filename):
"""
文件IO操作
:param soup:
:param filename:
:return:
"""
tags = soup.find_all(name="div", attrs={"class": "addrLeft"}, limit=10)
urls = []
ips = []
try:
for tag in tags:
tag = tag.find(name="span", attrs={"class": "aSpan"})
t = tag.find(name="a", attrs={"target": "_blank"})
ip = ""
url = ""
if t and t.has_attr('href'):
if t['href'][0:4] != 'http':
ip = "ip: " + t['href'][0:4] + "\n"
else:
url = "url: " + t['href'] + "\n"
if ip != "" and ip not in ips:
ips.append(ip)
if url != "" and url not in urls:
urls.append(url)
with open(filename, "a+", encoding="utf-8")as f:
if ips:
f.writelines(ips)
if urls:
f.writelines(urls)
return len(ips) + len(urls)
except Exception as e:
loguru.logger.error(e)
return False
def getReq(url, cookies, headers, timeout):
"""
请求 页数
:param url:
:param cookies:
:param headers:
:param timeout:
:return:
"""
while 1:
try:
time.sleep(timeout)
html = requests.get(url=url, cookies=cookies, headers=headers)
text = html.text
if 'Retry later' in text:
loguru.logger.warning("忙碌")
time.sleep(10)
continue
if html.status_code != 200:
time.sleep(timeout)
continue
return BeautifulSoup(text, "html.parser")
except Exception as e:
loguru.logger.error(e)
return False
class ThreadPool:
def __init__(self, maxWorkers):
self.pool = ThreadPoolExecutor(max_workers=maxWorkers)
self.taskQueue = queue.Queue()
self.futures = {}
def setTask(self, poc, target):
newTask = (poc, target)
self.taskQueue.put(newTask)
def thread(self):
while self.taskQueue.qsize() != 0:
currentTask = self.taskQueue.get()
currentPoc = currentTask[0]
currentTarget = currentTask[1]
future = self.pool.submit(currentPoc, *currentTarget)
self.futures[future] = currentTarget
self.futures = concurrent.futures.as_completed(self.futures)
return self.futures
ThreadPool 我这里是对原线程池函数进行了封装,任务多了也会出现bug 就是上万条的那种,我们这里不会遇到,所以讲究写了( 多线程不懂的话,我就真没法帮你了)
getReq 这个就是用请求到 每一页的结果,得到soup
getUrlIp 这个就是得到每页的url咯,详细逻辑 自己就慢慢看吧 也简单无非就是找到url 所在tag ,然后在保存到文件夹里面,也可以返回出来都行随便你
futureThree 这个就是多线程函数啦,讲上述得到的page,制作reqUrl 然后批量请求 得到结果,保存url。
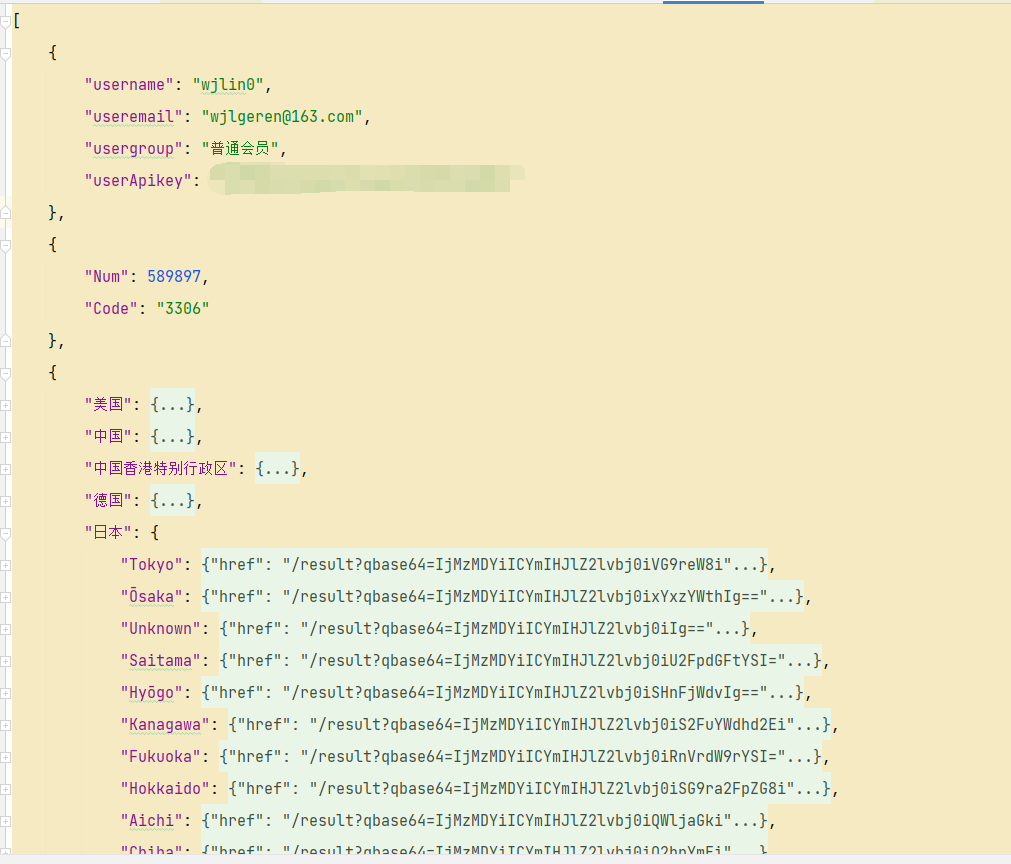
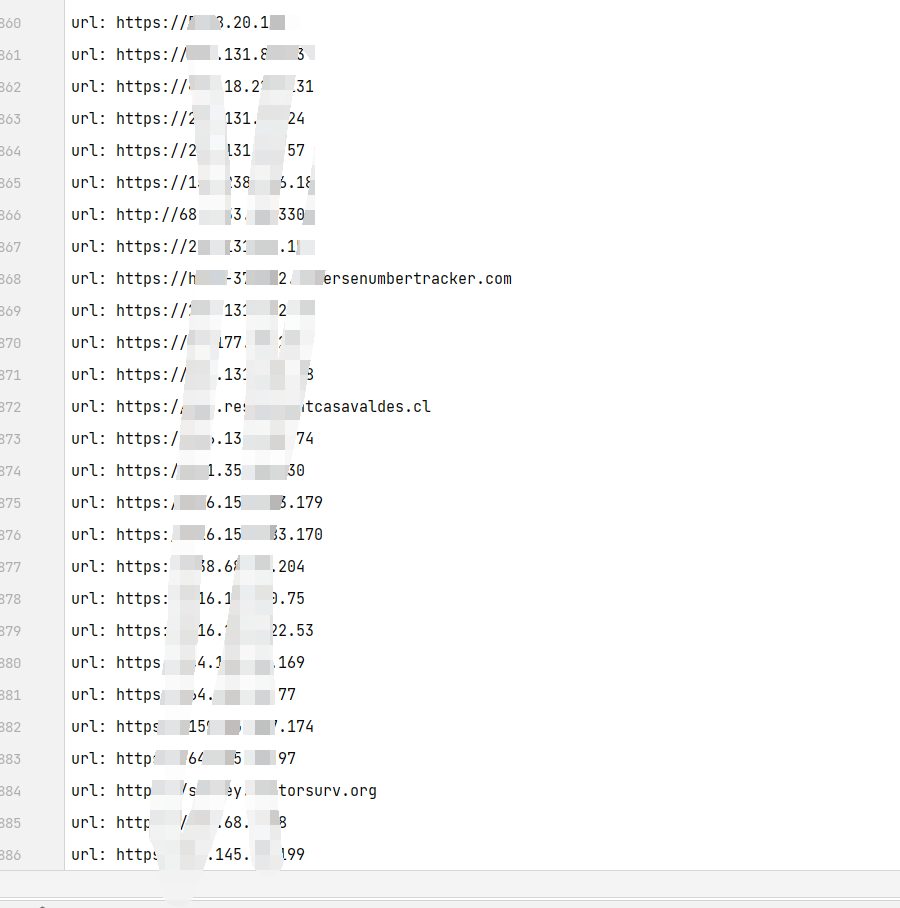
输出样式
最后就是输出的样式啦 两个文件 第一个是 都在outputs里面了,
看法
对于这次工具 开发看法的话,就是让我获得到爬虫的大量知识,让我学习到了多线程,多协程(这个在 v2.0 里面有体现。。协程太快了所以我就弃用了,那一部分的代码 也是开源的 链接在下面),requuest的使用,selenium的使用,配置文件的提取,click包的使用,loguru的使用 ,这些也是爬虫的基本知识了吧,还是收获不错的,
requests :get 、post、session
selenium:driver
- 配置文件:configparser的使用
- 参数:click的使用
- 输出:loguru
这次涉及的知识点就那么多了,还是很简单的,用心开发的话 700行代码 大约两三天就完成了,至于 我为啥一直在更新,是因为 额 对工具的执着吧,让更多功能呈现出来,没有做出GUI也是我的一大遗憾,不过哪位朋友来帮帮我做一下 ,也是不错滴 (有兴趣访问我的个人博客!!!里面有我的联系方式)
总结
里面还有很多很多不足的地方,我能想到的也就那么多 ,唉,我也只是一名普通的大三学生耶,其实有一个人 跟我一起开发 那这个工具不就更加完美了!到时候代码就开源啦这多好呀,是吧。
代码没有开源(理由 就是 不想让人白嫖呗,反正二进制包是有的 - windows10 windows 7 windows 11 都适用的 只要是amd64架构的都行 amd32 我不知道没试过),工具是有的(链接在下面)
再说一次吧 就是 找人!!!找 个一起开发的小伙伴 取长补短 啦