基于机器学习的ICP备案查询验证码识别技术研究
| 作者 | 修订时间 |
|---|---|
| 2025-10-15 00:38:37 |
(以 beian.miit.gov.cn 为例)
前沿
在日常搞安全、爬数据的时候,大家肯定都遇到过一个老熟人 —— 验证码。它像一个看门大爷一样,挡在各种接口和网页前面,尤其是在查ICP备案信息这类官方数据时,验证码几乎成了“标配”。
但验证码虽烦,也不是不能搞。特别是图像类验证码,用点机器学习的小技巧,搞定它其实没那么复杂。
这篇文章就来分享一下我是怎么利用机器学习来识别ICP备案查询页面上的验证码的 —— 包括怎么采集数据、怎么训练模型、最后怎么把它跑起来。希望对也在折腾这块的小伙伴有点参考价值。
工信部的验证码
要搞识别,第一步当然是先搞清楚“敌人”长啥样。
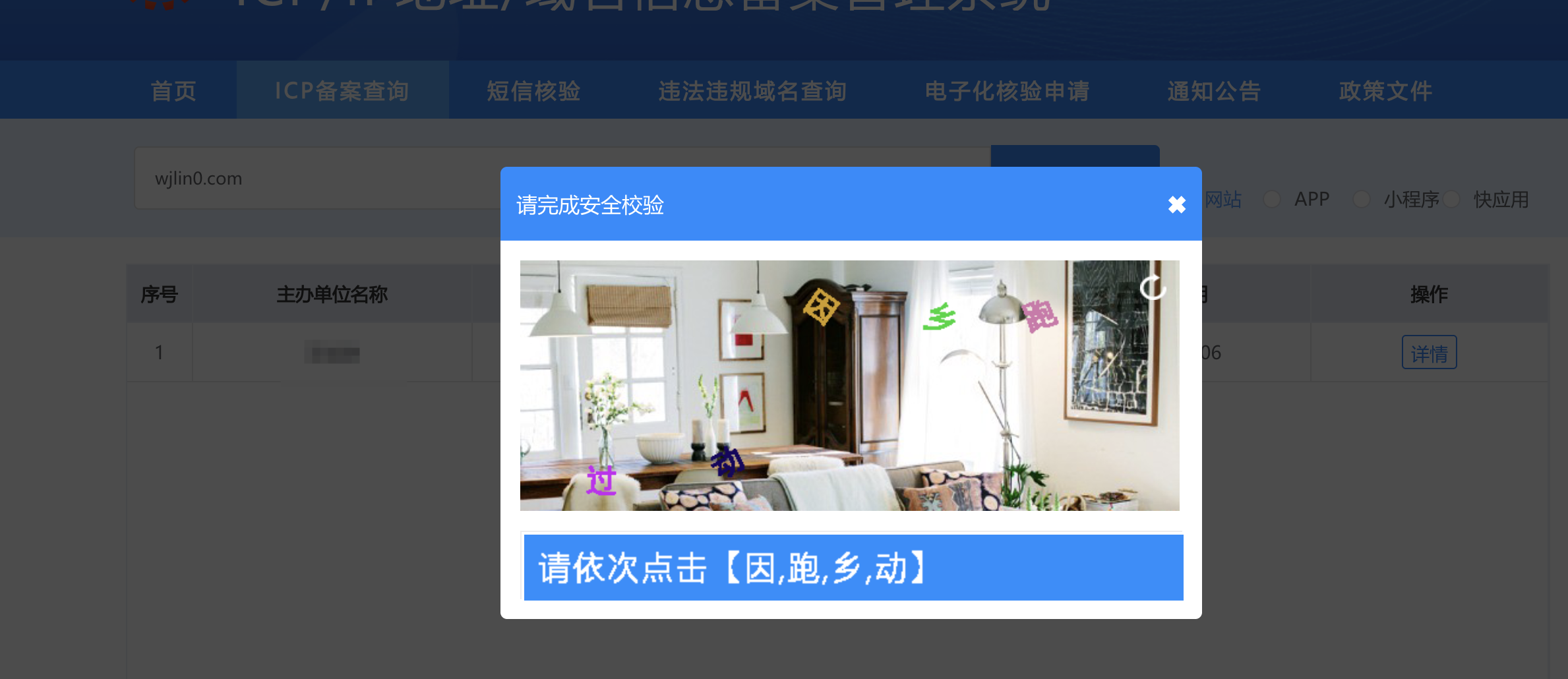
我们打开 ICP备案查询官网,随便点进“网站备案查询”这一栏,就能看到一个非常典型的验证码框。它用的是图形点选验证码,而且是中文的。具体长这样:
-
验证码分上下两部分上面部分是文件在图片中,下面部分是提示
-
验证码提示:**请依次点击【因, 跑, 乡, 动】
-
你需要用鼠标按顺序点击那 4 个字,系统才能通过验证
请求逻辑
先进行一次简单的查询,并利用Burp抓包工具获取当次的流量
很明显这里进行了三次请求
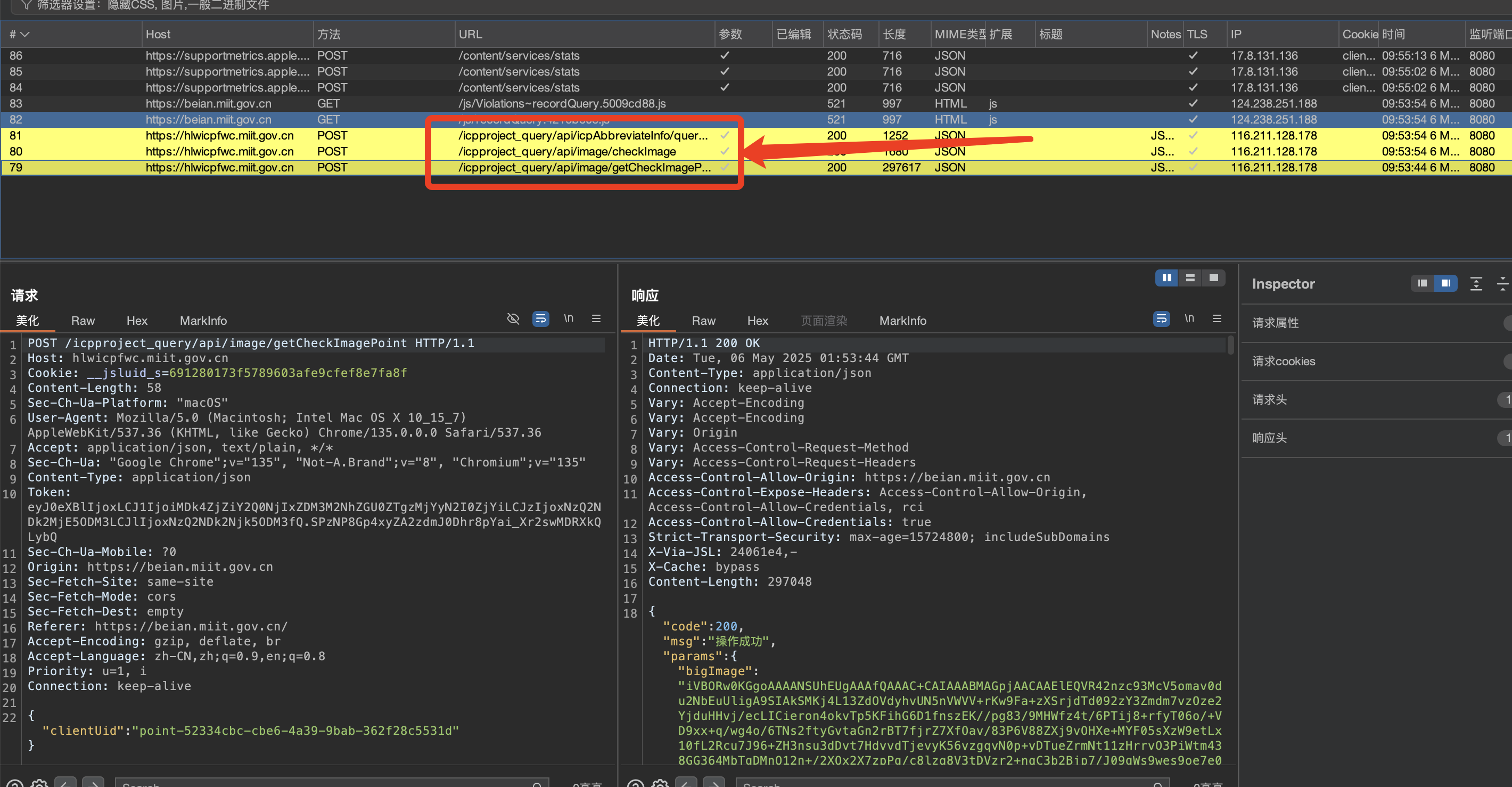
第一次请求,不难分析出是,获取了原始图片,bigImage和smallImage
POST /icpproject_query/api/image/getCheckImagePoint HTTP/1.1
Host: hlwicpfwc.miit.gov.cn
Cookie: __jsluid_s=691280173f5789603afe9cfef8e7fa8f
Content-Length: 58
Sec-Ch-Ua-Platform: "macOS"
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36
Accept: application/json, text/plain, */*
Sec-Ch-Ua: "Google Chrome";v="135", "Not-A.Brand";v="8", "Chromium";v="135"
Content-Type: application/json
Token: eyJ0eXBlIjoxLCJ1IjoiMDk4ZjZiY2Q0NjIxZDM3M2NhZGU0ZTgzMjYyN2I0ZjYiLCJzIjoxNzQ2NDk2MjE5ODM3LCJlIjoxNzQ2NDk2Njk5ODM3fQ.SPzNP8Gp4xyZA2zdmJ0Dhr8pYai_Xr2swMDRXkQLybQ
Sec-Ch-Ua-Mobile: ?0
Origin: https://beian.miit.gov.cn
Sec-Fetch-Site: same-site
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://beian.miit.gov.cn/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Priority: u=1, i
Connection: keep-alive
{"clientUid":"point-52334cbc-cbe6-4a39-9bab-362f28c5531d"}
响应结果(内容太多了,删掉了原始图片内容)
HTTP/1.1 200 OK
Date: Tue, 06 May 2025 01:53:44 GMT
Content-Type: application/json
Connection: keep-alive
Vary: Accept-Encoding
Vary: Accept-Encoding
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Access-Control-Allow-Origin: https://beian.miit.gov.cn
Access-Control-Expose-Headers: Access-Control-Allow-Origin, Access-Control-Allow-Credentials, rci
Access-Control-Allow-Credentials: true
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Via-JSL: 24061e4,-
X-Cache: bypass
Content-Length: 297048
{
"code": 200,
"msg": "操作成功",
"params": {
"bigImage": "xxxxxxx......",
"secretKey": "384sPbNakbrFsF1r",
"smallImage": "xxxxxxx......",
"uuid": "ca070c44c01b43668d4235efdc970ebc",
"wordCount": 4
},
"success": true
}
这两张图片其实就是 验证码的上下两部分

第二次请求,很明显是点选完成了进行验证。
POST /icpproject_query/api/image/checkImage HTTP/1.1
Host: hlwicpfwc.miit.gov.cn
Cookie: __jsluid_s=691280173f5789603afe9cfef8e7fa8f
Content-Length: 255
Sec-Ch-Ua-Platform: "macOS"
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36
Accept: application/json, text/plain, */*
Sec-Ch-Ua: "Google Chrome";v="135", "Not-A.Brand";v="8", "Chromium";v="135"
Content-Type: application/json
Token: eyJ0eXBlIjoxLCJ1IjoiMDk4ZjZiY2Q0NjIxZDM3M2NhZGU0ZTgzMjYyN2I0ZjYiLCJzIjoxNzQ2NDk2MjE5ODM3LCJlIjoxNzQ2NDk2Njk5ODM3fQ.SPzNP8Gp4xyZA2zdmJ0Dhr8pYai_Xr2swMDRXkQLybQ
Sec-Ch-Ua-Mobile: ?0
Origin: https://beian.miit.gov.cn
Sec-Fetch-Site: same-site
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://beian.miit.gov.cn/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Priority: u=1, i
Connection: keep-alive
{"token":"ca070c44c01b43668d4235efdc970ebc","secretKey":"384sPbNakbrFsF1r","clientUid":"point-52334cbc-cbe6-4a39-9bab-362f28c5531d","pointJson":"vRXxnZ1ujKsfNKB1AmvokXOxQwt1DMyQ9ZJyVLTkM6/9FW6R6EudYrEqGRoxFP+ugNRpqCu1S1hM2mzn4VbQyBAwpqCviXt8GV+57Jh6V3g="}
验证通过后会返回sign
HTTP/1.1 200 OK
Date: Tue, 06 May 2025 01:53:54 GMT
Content-Type: application/json
Connection: keep-alive
Vary: Accept-Encoding
Vary: Accept-Encoding
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Access-Control-Allow-Origin: https://beian.miit.gov.cn
Access-Control-Expose-Headers: Access-Control-Allow-Origin, Access-Control-Allow-Credentials, rci
Access-Control-Allow-Credentials: true
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Via-JSL: 24061e4,-
X-Cache: bypass
Content-Length: 1113
{"code":200,"msg":"操作成功","params":{"sign":"eyJ0eXBlIjozLCJleHREYXRhIjp7InZhZnljb2RlX2ltYWdlX2tleSI6ImNhMDcwYzQ0YzAxYjQzNjY4ZDQyMzVlZmRjOTcwZWJjIn0sImUiOjE3NDY0OTY3MzQ3Mjd9.puSMuFYBv6rcSE7eTUCs_PLUobRSf8kQ76-XuZ40I_Y","smallImage":"iVBORw0KGgoAAAANSUhEUgAAAfQAAAAyCAYAAACqECmXAAACSElEQVR42u3dzWrrMBCA0bz/po+crgqlJJY0M5Kl5gTO4hbs4HDhi/XjPB5fzycAcDgfAgAIOgAg6ACAoAMAgg4Agg4ACDoAIOgAgKADgKADAIIOAAg6AHBf0H9es4/Z8Tp2fh8APjToV69ZQf99XPZVGdrK8wo6ANsHPRPVv8ftGvTq+Ao6AMuH3K/ik43q6LGzQ/jq/JEvNa3PRdABmB70d8PgVcPzPUPvOwW9530FHYB/EfRInCOBi4aw+pW9018xfQCAoDeDfhWeHReTCToAgj54F14Rpuqh6tVD+r1D9BbMATB9lXvrznL0jnhkId3dQc8GVdABOCbo0SHkE4M+GnpBB2CroPcErnquOfq+2Tn07Na1yFY/QQdgetBXLNQ6IeiR6xd0AI4LesXit7uG3O8M+l177QH4kFXurcj0BC/7DPjVQW9da+W+ekEHQNAFHQBBnxP0nr3rJwY9s3bg3TlGngvvPzAAoaBfzZu3olQR9JHV9TODXnFnLugAbB/01r+j29ZmBb1nv3tmhKB3Bf3M35YHQNBD8749QZ8xNF05n927Na5qiF7QAdhqDj276KsnnrOCnn2KXcWceuaLFQCCno559CdVI6GrCurVnf/V30evuyrmgg7A0qBXxWh10DOjBJkHzGS/4AAg6CVbrlpD1tFHxlacOztE3vsjMZk4j5xbzAE4Luijq8VnBD0b5uhohZgDsHxRHAAg6ACAoAOAoPsQAEDQAQBBBwAEHQAQdAAQdABA0AEAQQcABB0ABB0A2Mk3SUNFSvkMxFcAAAAASUVORK5CYII="},"success":true}
第三次请求,就是查询了,带着第二次请求的sign,进行请求
POST /icpproject_query/api/icpAbbreviateInfo/queryByCondition HTTP/1.1
Host: hlwicpfwc.miit.gov.cn
Cookie: __jsluid_s=691280173f5789603afe9cfef8e7fa8f
Content-Length: 67
Sec-Ch-Ua-Platform: "macOS"
Sign: eyJ0eXBlIjozLCJleHREYXRhIjp7InZhZnljb2RlX2ltYWdlX2tleSI6ImNhMDcwYzQ0YzAxYjQzNjY4ZDQyMzVlZmRjOTcwZWJjIn0sImUiOjE3NDY0OTY3MzQ3Mjd9.puSMuFYBv6rcSE7eTUCs_PLUobRSf8kQ76-XuZ40I_Y
Sec-Ch-Ua: "Google Chrome";v="135", "Not-A.Brand";v="8", "Chromium";v="135"
Sec-Ch-Ua-Mobile: ?0
Uuid: ca070c44c01b43668d4235efdc970ebc
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36
Accept: application/json, text/plain, */*
Content-Type: application/json
Token: eyJ0eXBlIjoxLCJ1IjoiMDk4ZjZiY2Q0NjIxZDM3M2NhZGU0ZTgzMjYyN2I0ZjYiLCJzIjoxNzQ2NDk2MjE5ODM3LCJlIjoxNzQ2NDk2Njk5ODM3fQ.SPzNP8Gp4xyZA2zdmJ0Dhr8pYai_Xr2swMDRXkQLybQ
Origin: https://beian.miit.gov.cn
Sec-Fetch-Site: same-site
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://beian.miit.gov.cn/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Priority: u=1, i
Connection: keep-alive
{"pageNum":"","pageSize":"","unitName":"baidu.com","serviceType":1}
HTTP/1.1 200 OK
Date: Tue, 06 May 2025 01:53:54 GMT
Content-Type: application/json
Connection: keep-alive
Vary: Accept-Encoding
Vary: Accept-Encoding
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Access-Control-Allow-Origin: https://beian.miit.gov.cn
Access-Control-Expose-Headers: Access-Control-Allow-Origin, Access-Control-Allow-Credentials, rci
Access-Control-Allow-Credentials: true
rci: 13b2f3eed0d64d9ba0f32d7b3c5e3149
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Via-JSL: 24061e4,-
X-Cache: bypass
Content-Length: 647
{"code":200,"msg":"操作成功","params":{"endRow":0,"firstPage":1,"hasNextPage":false,"hasPreviousPage":false,"isFirstPage":true,"isLastPage":true,"lastPage":1,"list":[{"contentTypeName":"","domain":"baidu.com","domainId":10000245113,"leaderName":"","limitAccess":"否","mainId":282751,"mainLicence":"京ICP证030173号","natureName":"企业","serviceId":282911,"serviceLicence":"京ICP证030173号-1","unitName":"北京百度网讯科技有限公司","updateRecordTime":"2019-05-16 16:06:21"}],"navigatePages":8,"navigatepageNums":[1],"nextPage":1,"pageNum":1,"pageSize":10,"pages":1,"prePage":1,"size":1,"startRow":0,"total":1},"success":true}
参数分析
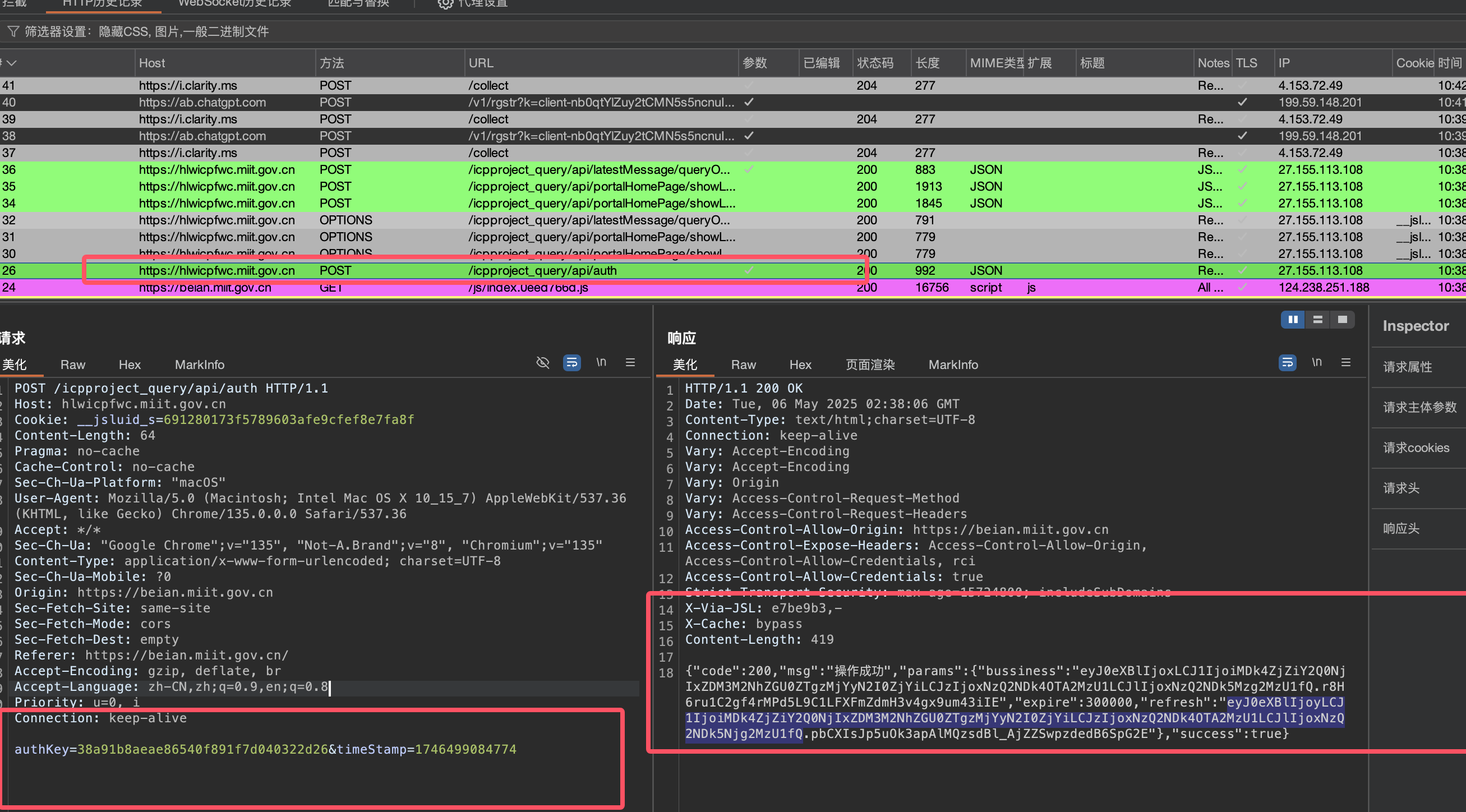
Token
我们首先分析Token从哪里来的,可以从上面的三次请求发现,每次请求都携带了Token 那么 token 从哪里来呢?
我们先清理一遍浏览器,并刷新
可以看到这里的请求包,是用来获取Token的
分析一下前端代码
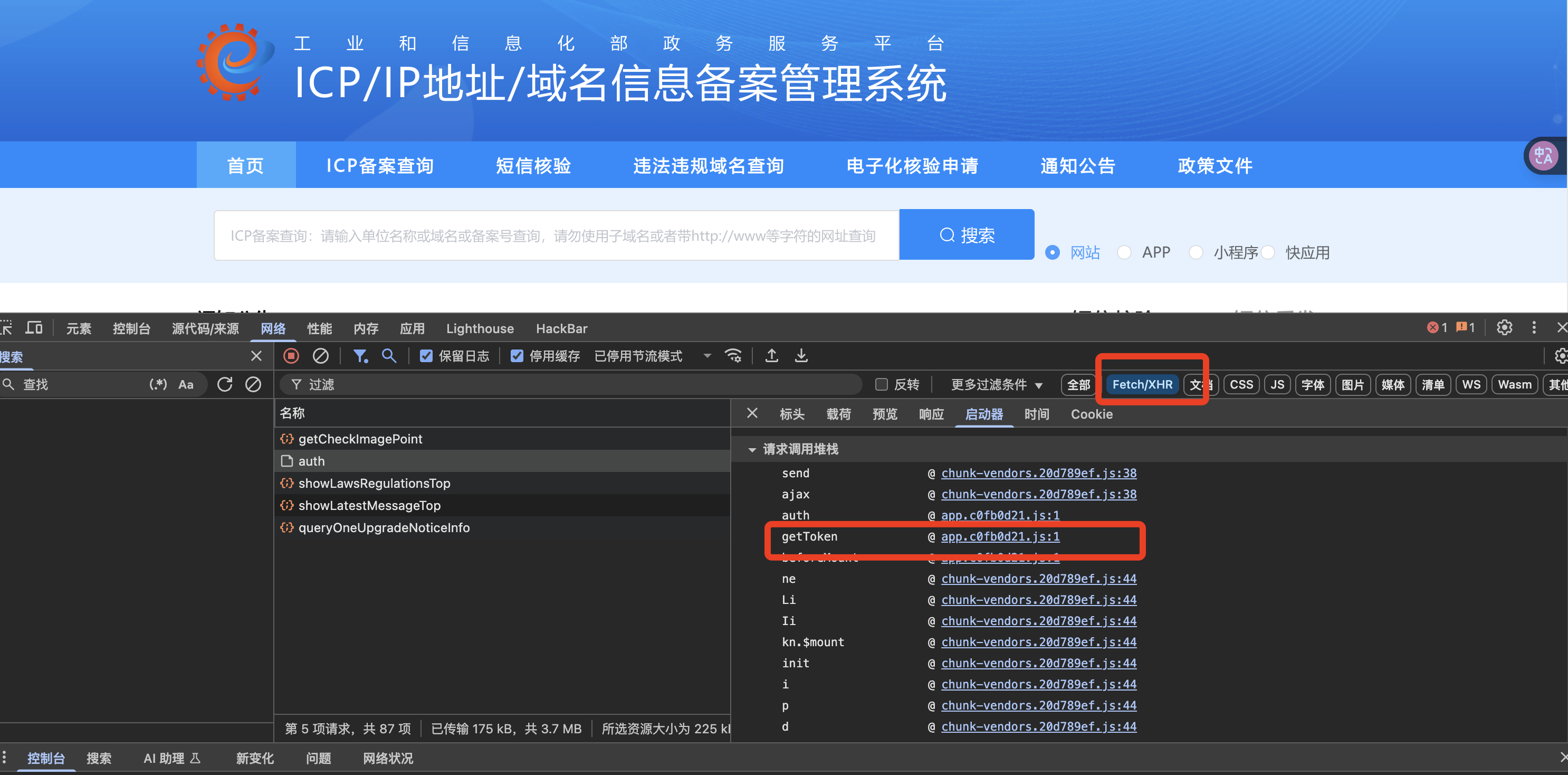
跟进调试
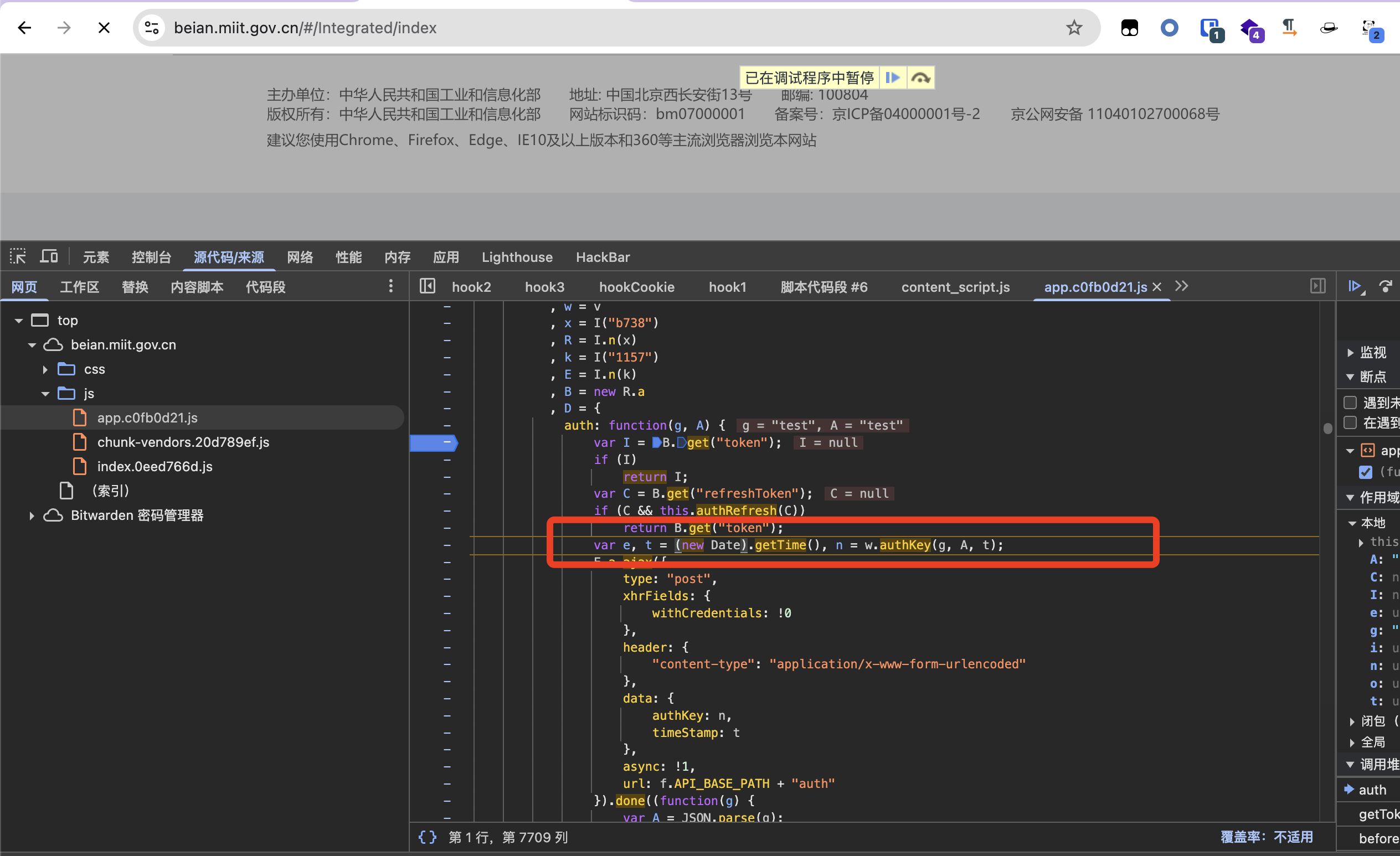
这个auth 就是 testtest+时间戳的md5
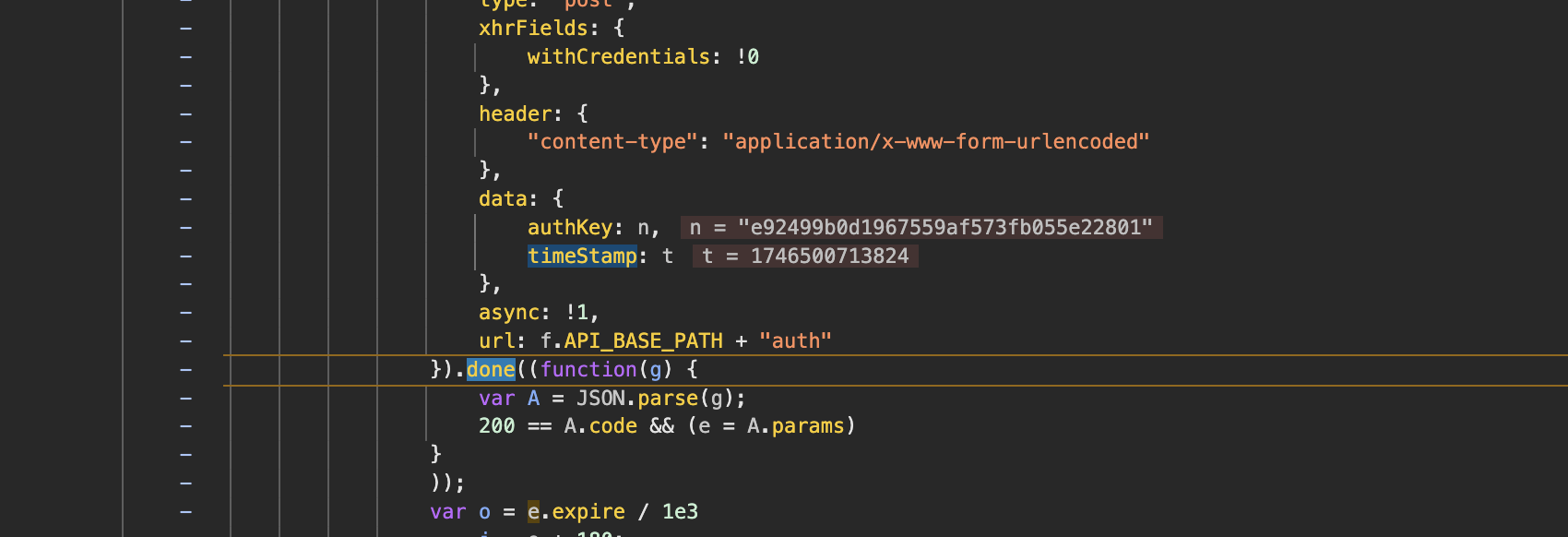
pointJson
那么接下来,查看第二次请求的pointJson是如何来的
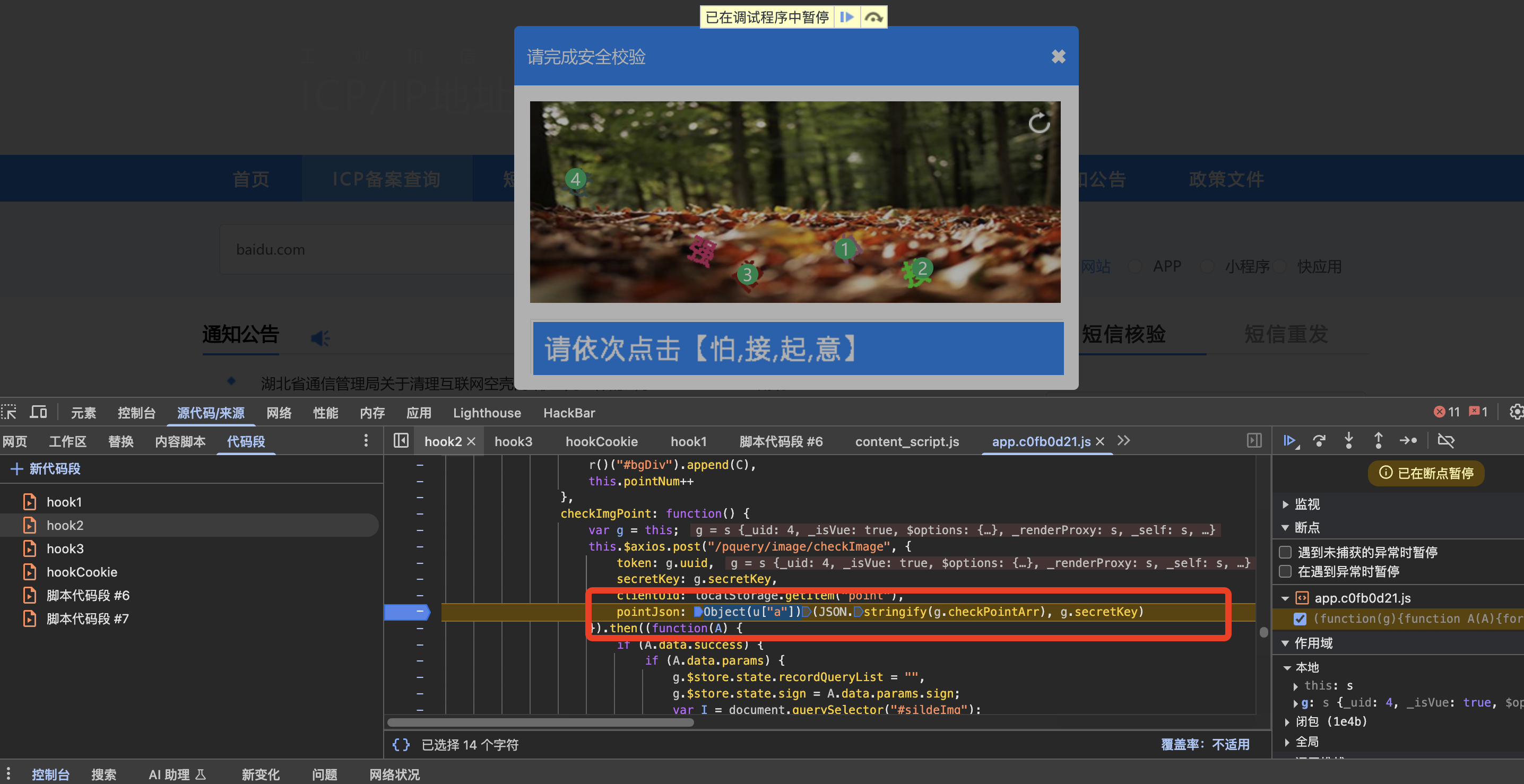
这个 checkPointArr就是这4个点
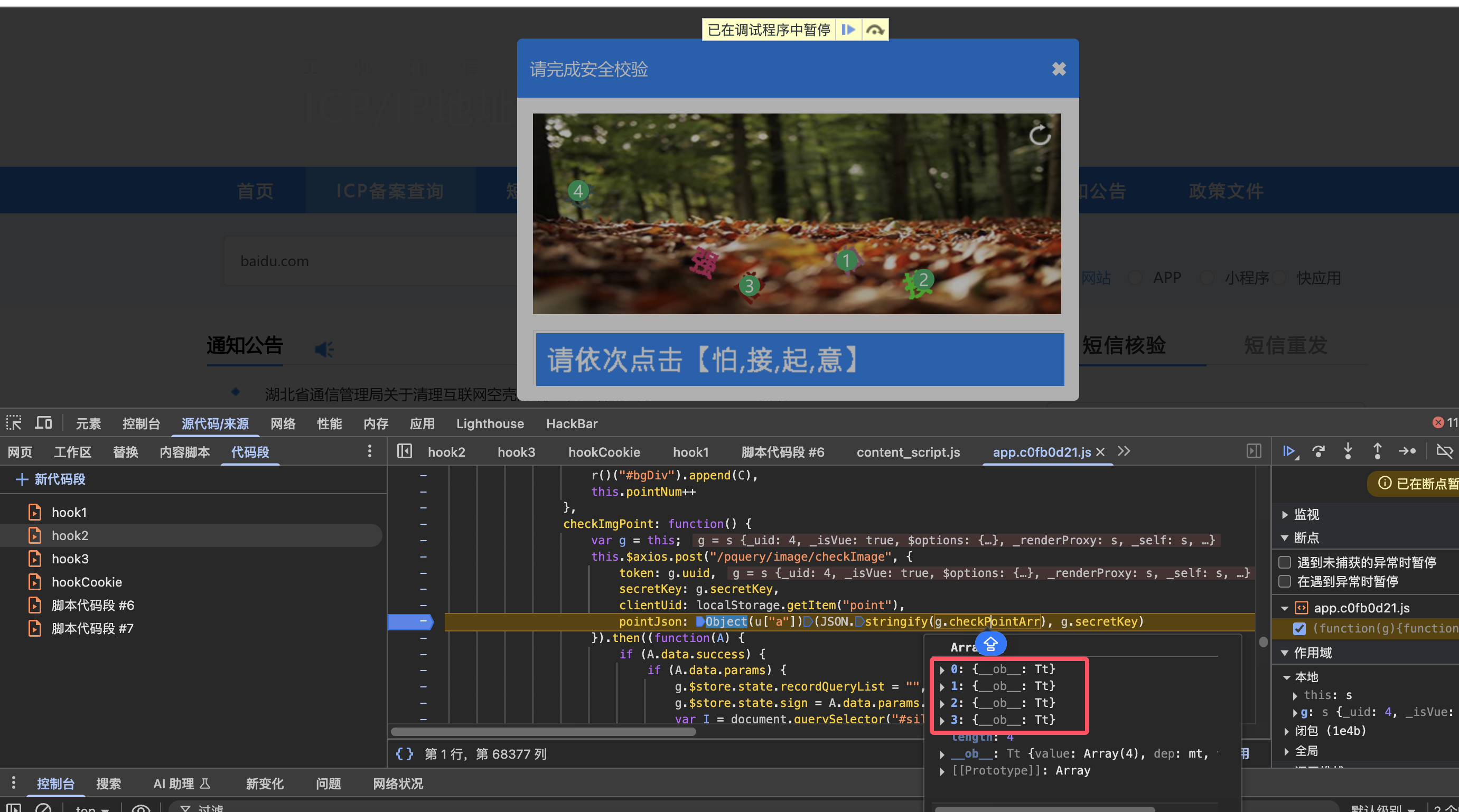
跟进调试发现是 AES Pkcs7填充加密
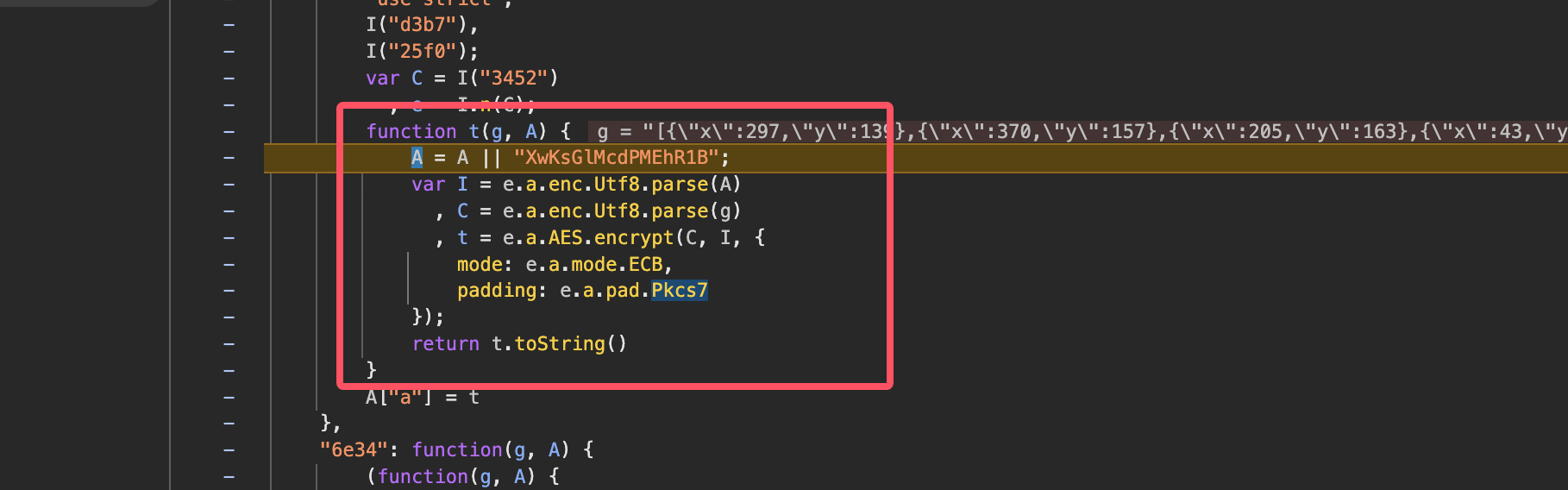
那么现在关键的来了,checkPointArr 这4个点从哪里来,就是我们接下来的重点了
checkPointArr
可以看到他是获取的图片坐标,并添加画圆
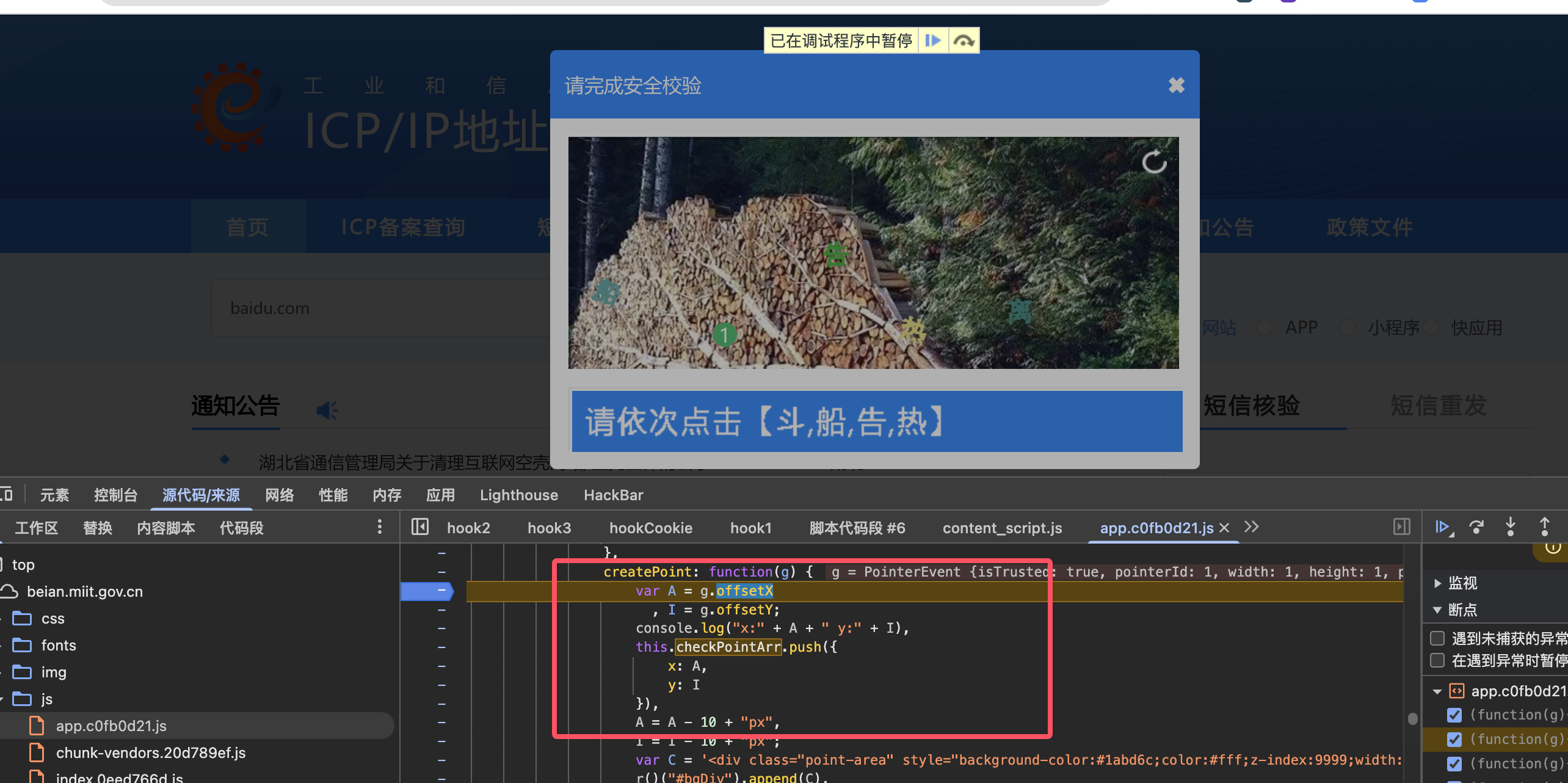
添加后,又进行了画圆的操作

4个点选完后,触发 checkImgPoint
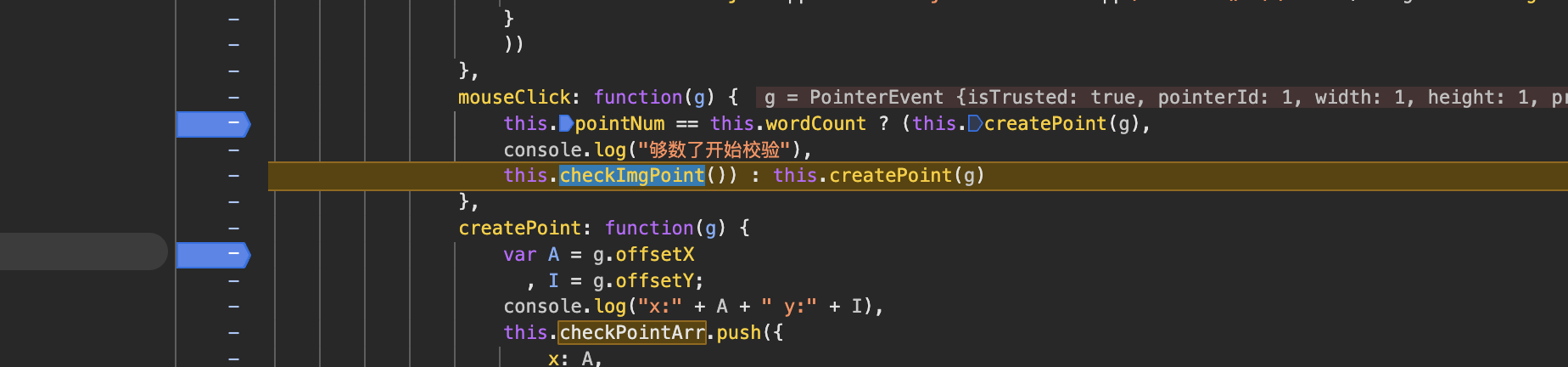
我们跟进调试,发现就是请求函数
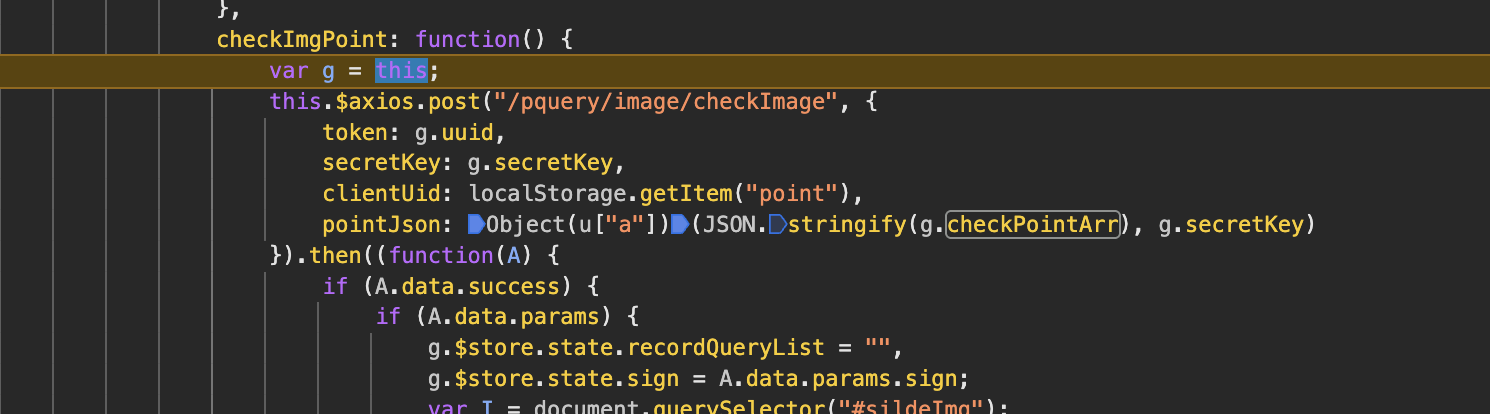
所以,我们要实现验证码的自动化,就要让脚本知道这4个点的位置,那么该怎么做呢?
点选验证码的自动化
让模型学会点字
点选验证码,传统方法大多是人眼自己看图、自己选,但我们今天的目标很明确:让机器做这些事——自动从图片中识别汉字,按顺序点击。整个过程分为两步:识别图中的汉字位置,然后根据提供的提示字,按正确顺序点击。
两步走:从图像到点击
- 图像识别: 首先,模型需要识别出图中的 5 个汉字。也就是从整个验证码图片中提取出每个字的坐标,这一步就像让模型具备“看图”的能力,准确找出每个字的位置。
- 字匹配与排序: 然后,模型根据目标提示,判断图中的哪个字是正确的,并按顺序给出点击顺序。这就相当于“配对”工作,模型要能够判断每个字和提示字的相似度,并按正确的顺序进行排列。
看起来这很简单,但实际上,这两步可不简单,尤其是图中的干扰信息和字体的变化,给了传统方法不小的挑战。所以,我们需要借助机器学习,尤其是深度学习,来提高识别的准确性。
接下来的步骤将详细介绍如何利用 YOLOv5 来识别图中的字,并使用孪生网络进行字匹配。最终,我们会把这些信息转化成可以提交的 pointson 参数。
先把字抠出来,提取每个字的位置
验证码中的 5 个字需要通过准确的图像处理技术提取出来,才能进一步处理并进行点击。为了实现这个目标,我们将使用 YOLOv11 模型来检测每个汉字的位置,YOLOv11 是 YOLO 系列的最新版本,相比之前的版本在精度和效率上有了进一步提升。
YOLOv11 是最新的目标检测模型,相比 YOLOv5 和其他版本,它在多种标准数据集上都有更强的表现,能够实现更快的推理速度和更高的精度。对于验证码图片来说,我们将用 YOLOv11 来检测汉字的坐标,为后续的点击顺序匹配打下基础。
数据集准备
首先,我们需要准备一个包含大量验证码图像和对应标注数据的训练集。标注的内容是每个汉字的矩形框,指示其在图像中的位置。我们可以使用像 labelImg 这样的工具进行手动标注,给每个汉字打上标签并记录其坐标。
使用下面代码
def getImage(token):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://beian.miit.gov.cn/",
"Token": token,
"Connection": "keep-alive",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://beian.miit.gov.cn"
}
payload = {
"clientUid": "point-" + str(uuid.uuid4())
}
try:
resp = requests.post("https://hlwicpfwc.miit.gov.cn/icpproject_query/api/image/getCheckImagePoint",
headers=headers, json=payload, verify=False).json()
return resp["params"], payload["clientUid"]
except Exception:
time.sleep(5)
resp = requests.post("https://hlwicpfwc.miit.gov.cn/icpproject_query/api/image/getCheckImagePoint",
headers=headers, json=payload, verify=False).json()
return resp["params"], payload["clientUid"]
def auth():
t = str(round(time.time()))
data = {
"authKey": hashlib.md5(("testtest" + t).encode()).hexdigest(),
"timeStamp": t
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://beian.miit.gov.cn/",
"Content-Type": "application/x-www-form-urlencoded",
"Connection": "keep-alive",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://beian.miit.gov.cn"
}
try:
resp = requests.post("https://hlwicpfwc.miit.gov.cn/icpproject_query/api/auth", headers=headers,
data=parse.urlencode(data), verify=False).text
return json.loads(resp)["params"]["bussiness"]
except Exception:
time.sleep(5)
resp = requests.post("https://hlwicpfwc.miit.gov.cn/icpproject_query/api/auth", headers=headers,
data=parse.urlencode(data), verify=False).text
return json.loads(resp)["params"]["bussiness"]
def get_origin_data(save_dir="origin_data", max_images=100):
"""
获取验证码图片并保存到指定目录。如果发生异常,会重新尝试获取剩余数量的图片。
:param save_dir: 图片保存的目录,默认为 "data/img/big/"
:param max_images: 最大保存的图片数量,默认为 100
"""
token = auth()
time.sleep(0.1)
# 确保保存目录存在
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 记录已获取的图片数量
images_saved = 0
while images_saved < max_images:
try:
for i in range(images_saved, max_images): # 获取指定数量的图片
print(f"正在获取第{i + 1}张验证码") # i 从 0 开始,所以显示为 i + 1
# 每5次重新获取token
if i % 5 == 0:
token = auth()
time.sleep(0.1)
params, clientUid = getImage(token) # 获取图片信息
# 如果params为空或异常,继续
if not params:
raise ValueError("获取验证码数据失败,重新尝试...")
# 生成随机文件名
filename = random_filename() + ".jpg"
save_path = os.path.join(save_dir, filename)
# 保存图片
with open(save_path, "wb") as f:
f.write(base64.b64decode(params["bigImage"]))
print(f"第{i + 1}张验证码已保存为 {filename}")
images_saved += 1 # 增加已保存的图片数量
time.sleep(1.5)
except Exception as e:
print(f"错误: {e},正在重新尝试获取剩余的 {max_images - images_saved} 张验证码")
# 如果发生异常,继续从剩余图片数开始
time.sleep(2) # 等待一会后重新尝试
continue
讲得到的图片集,进行手动标注 使用 labelImg
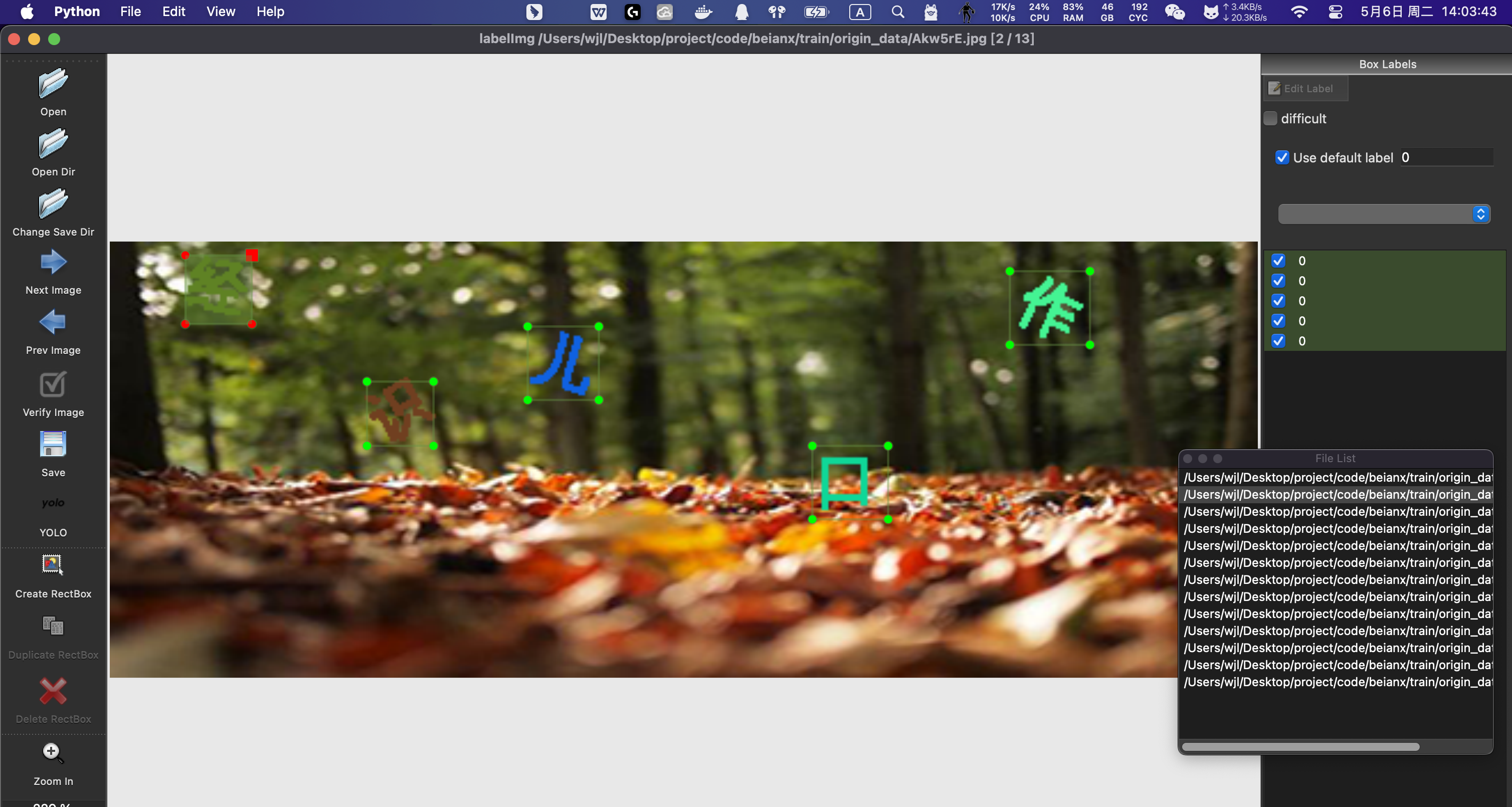
这里有几个快捷键
- W:画框
- A:上一张
- D:一下涨
- command + v:复制上一张的画框
大概标注 200-300张图片即可
训练 YOLOv11
利用标注好的数据集来训练 YOLOv11 模型
首先对原始图片进行拆分,进行8:2 进行才分为 train和val 目录
def split(p=os.path.join("datasets", "all")):
dataset_path = p
images_path = os.path.join(dataset_path, "images")
labels_path = os.path.join(dataset_path, "labels")
output_dir = "datasets" # 输出的拆分目录
train_ratio = 0.8
val_ratio = 0.2
# test_ratio = 0.1
# 确保比例加和为1
# assert train_ratio + val_ratio == 1.0
# 创建输出目录
for split in ["train", "val"]:
os.makedirs(os.path.join(output_dir, split, "images"), exist_ok=True)
os.makedirs(os.path.join(output_dir, split, "labels"), exist_ok=True)
# 获取所有图片文件名
image_files = [f for f in os.listdir(images_path) if f.endswith(('.jpg', '.png'))]
random.shuffle(image_files)
# 计算拆分数量
total_images = len(image_files)
train_count = int(total_images * train_ratio)
val_count = int(total_images * val_ratio)
# 拆分数据集
train_files = image_files[:train_count]
val_files = image_files[train_count:train_count + val_count]
# 拷贝文件函数
def copy_files(file_list, split):
for file in file_list:
# 复制图片
src_image_path = os.path.join(images_path, file)
dst_image_path = os.path.join(output_dir, split, "images", file)
shutil.copy(src_image_path, dst_image_path)
# 复制标签
label_file = file.replace('.jpg', '.txt').replace('.png', '.txt')
src_label_path = os.path.join(labels_path, label_file)
dst_label_path = os.path.join(output_dir, split, "labels", label_file)
if os.path.exists(src_label_path): # 确保标签文件存在
shutil.copy(src_label_path, dst_label_path)
# 拷贝到不同集合
copy_files(train_files, "train")
copy_files(val_files, "val")
print("数据集拆分完成!")
拆分完成后进行训练
def train(train_model="yolo11n.pt"):
model = YOLO(train_model)
# 文字
model.train(data="./dataset.yaml", epochs=100, imgsz="190,500", device="mps")
#
# # Export the model to ONNX format
model.export(format="onnx", imgsz="190,500")
dataset.yaml
train: train
val: val # 验证集图像路径
test: test # 测试集图像路径
nc: 1 # 只有一个类别
names: ['0']
训练完成后 会生成 模型文件 best.onnx
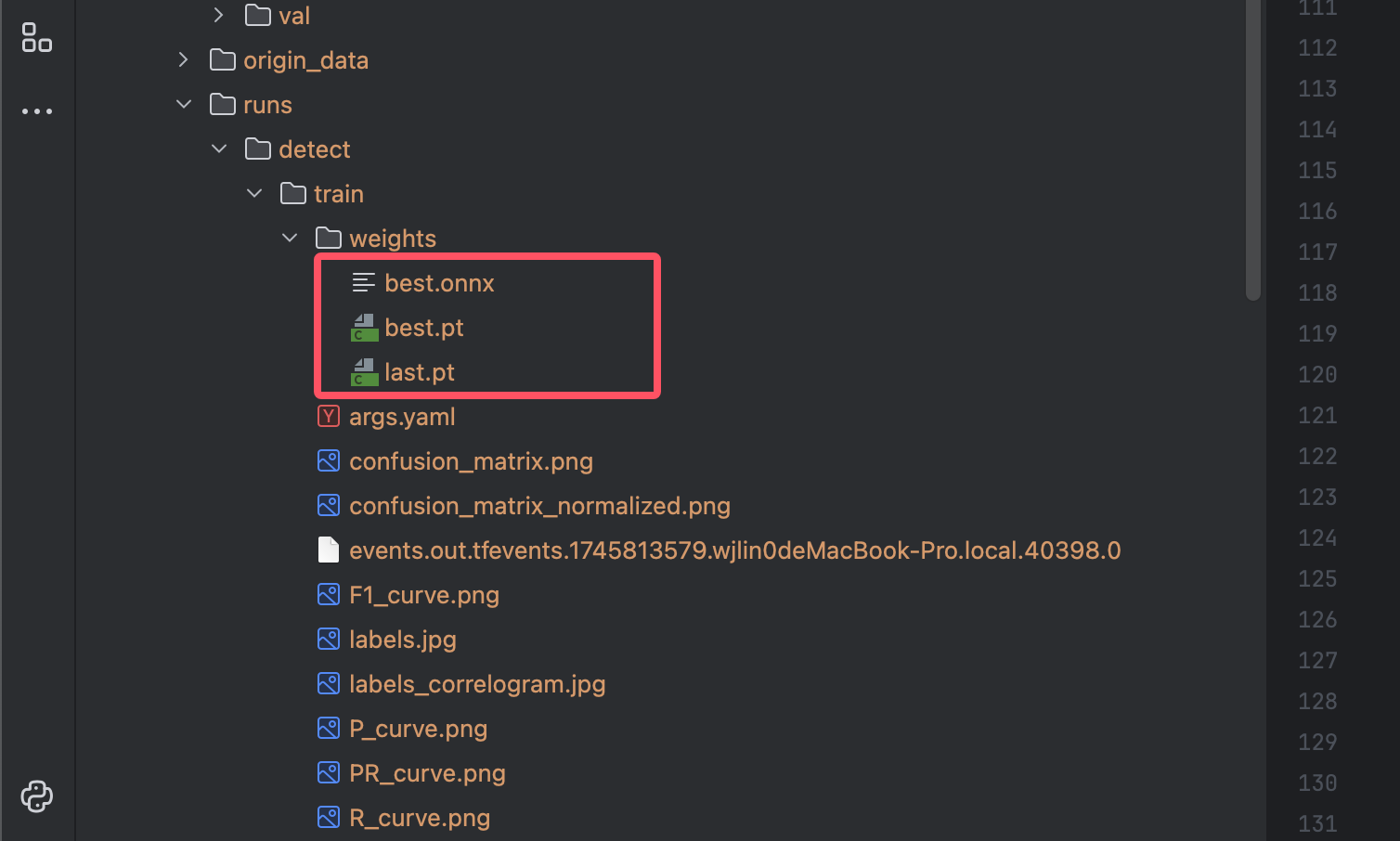
图像推理与提取
训练好的 YOLOv11 模型可以用来对实际的验证码图像进行推理。它会在图像中输出多个矩形框,每个框的坐标标示一个识别到的汉字的位置。模型会同时提供每个框的置信度,表示它对这个字的识别信心。
训练完成后,用下面的代码进行测试 查看 5个图片是否满足要求
def test(big_img="", onnx="best.onnx", confidence_thres=0.7, iou_thres=0.7):
if big_img == "":
token = auth()
time.sleep(0.1)
params, clientUid = getImage(token) # 获取图片信息
big_img = read_base64_image(base64_string=params["bigImage"])
else:
big_img = read_base64_image(big_img)
session = onnxruntime.InferenceSession(onnx)
model_inputs = session.get_inputs()
# 读取图像并处理
img_height, img_width = big_img.shape[:2]
img = cv2.cvtColor(big_img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (512, 192))
image_data = np.array(img) / 255.0
image_data = np.transpose(image_data, (2, 0, 1))
image_data = np.expand_dims(image_data, axis=0).astype(np.float32)
input = {model_inputs[0].name: image_data}
output = session.run(None, input)
outputs = np.transpose(np.squeeze(output[0]))
rows = outputs.shape[0]
boxes, scores = [], []
x_factor = img_width / 512
y_factor = img_height / 192
for i in range(rows):
classes_scores = outputs[i][4:]
max_score = np.amax(classes_scores)
if max_score >= confidence_thres:
x, y, w, h = outputs[i][0], outputs[i][1], outputs[i][2], outputs[i][3]
left = int((x - w / 2) * x_factor)
top = int((y - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
boxes.append([left, top, width, height])
scores.append(max_score)
indices = cv2.dnn.NMSBoxes(boxes, scores, confidence_thres, iou_thres)
if len(indices) < 5:
print("检测框数量不足5个")
return False
indices = indices[:5]
for idx in indices: # 使用 indices.flatten() 展开为一维数组
box = boxes[idx] # 获取框
x, y, w, h = box[0], box[1], box[2], box[3]
# 防止越界
x1 = max(0, x)
y1 = max(0, y)
x2 = min(x + w, img_width)
y2 = min(y + h, img_height)
# 裁剪图片
cropped_img = big_img[y1:y2, x1:x2]
# 保存图片
save_path = f"cut_image_{idx}.jpg"
cv2.imwrite(save_path, cropped_img)
print(f"保存图片到 {save_path}")
pass
用孪生网络做了个比一比
- 前面我们已经用 YOLOv11 把验证码图片里的 5 个字抠出来了,但这些字是图像,不是文本。与此同时,验证码的提示信息(比如“请按顺序点击:强、光、爱、国”)给的是文字内容。
- 模板字从提示区域截出来
- 最终模型选出匹配得分最高的 4 个,按位置排序
四、生成最终的 pointson 参数
- 把 4 个字的位置 → 生成 4 个点坐标
- 按顺序组织好构造成 pointson 参数
- 示例结构 or 抓包参考一下真实样子
五、结果还行吗?
- 成功率测试
- 错误的主要点在哪儿(识别不准?匹配失败?)
- 有啥优化空间(增强图像、加数据、多训练)